A New Dataset and Benchmark for Grounding Multimodal Misinformation
1School of Computer Science, Wuhan University
2Peking University
3School of Computing, National University of Singapore
2Peking University
3School of Computing, National University of Singapore
Technical Report
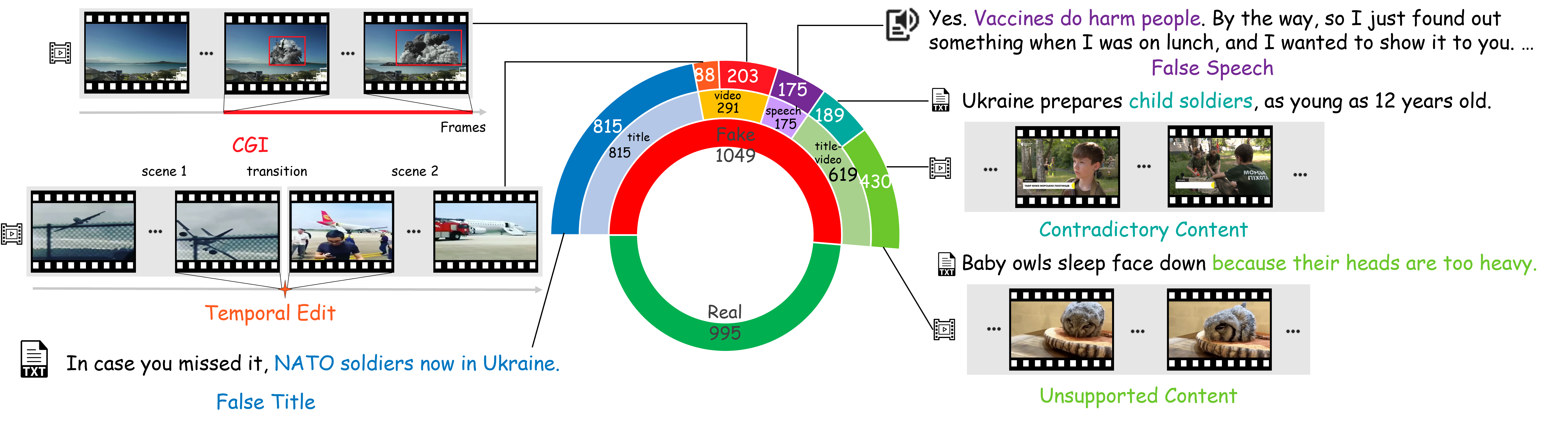
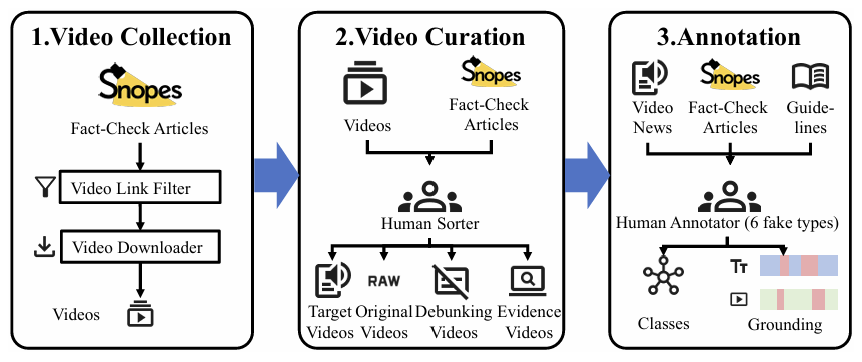
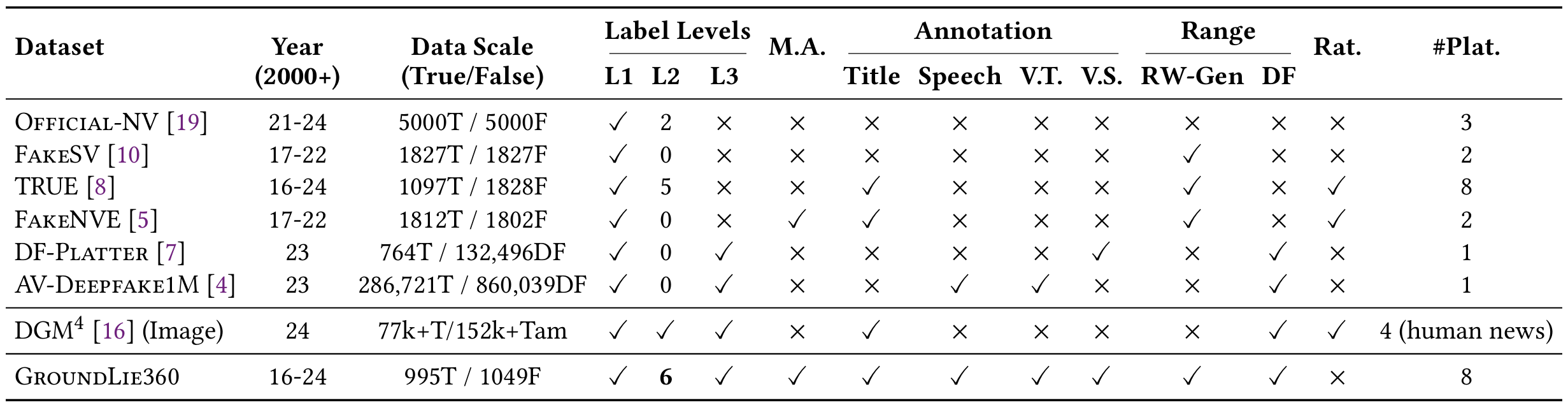
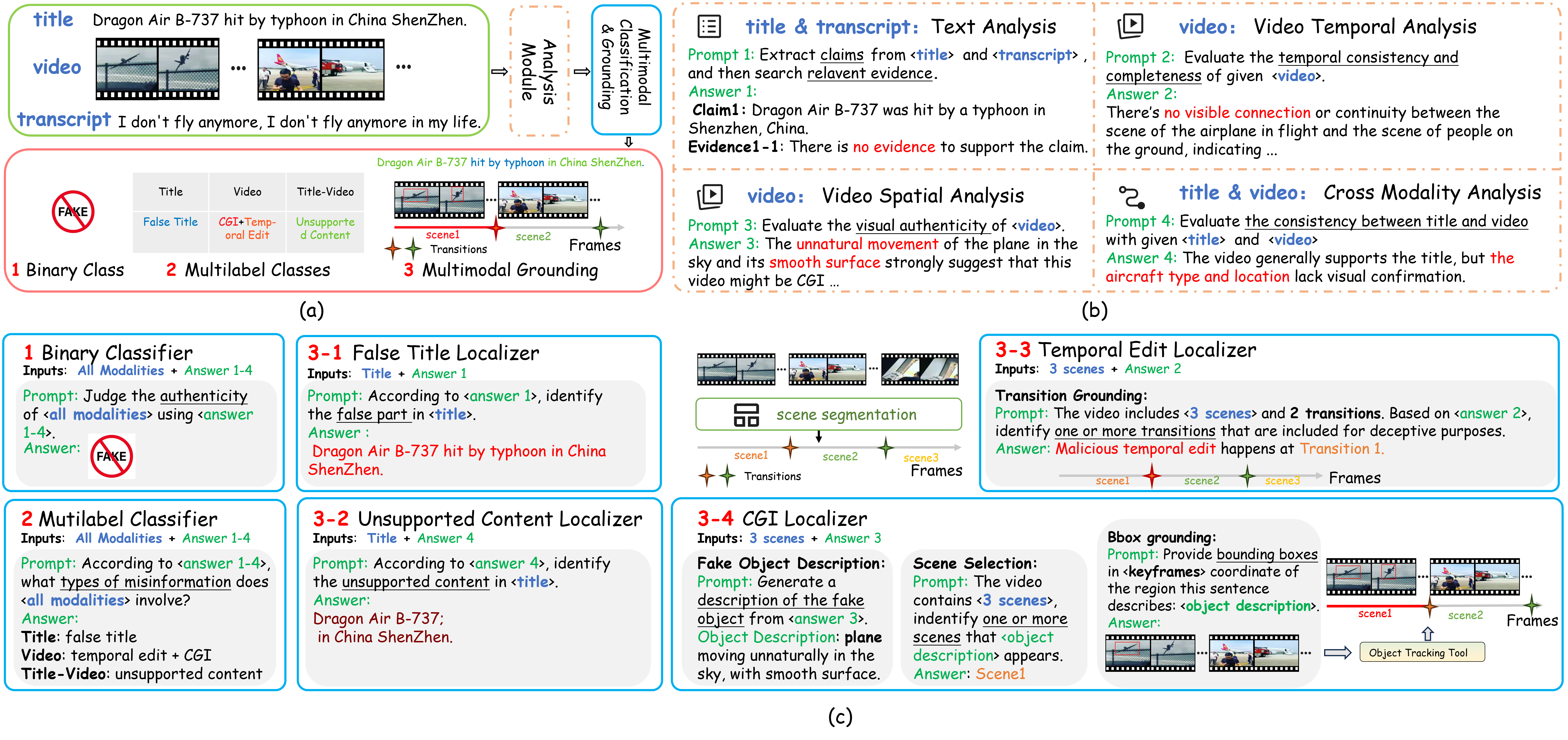
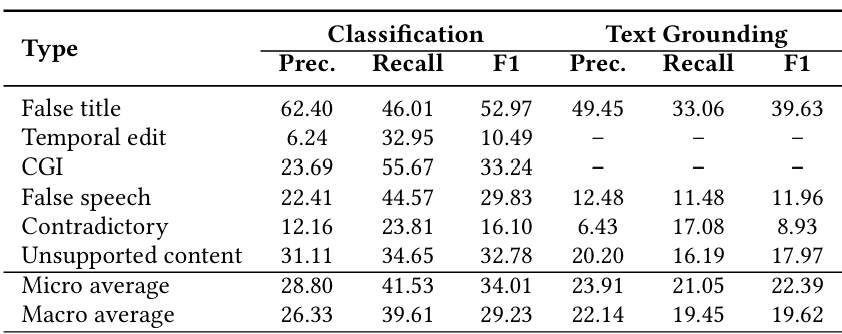
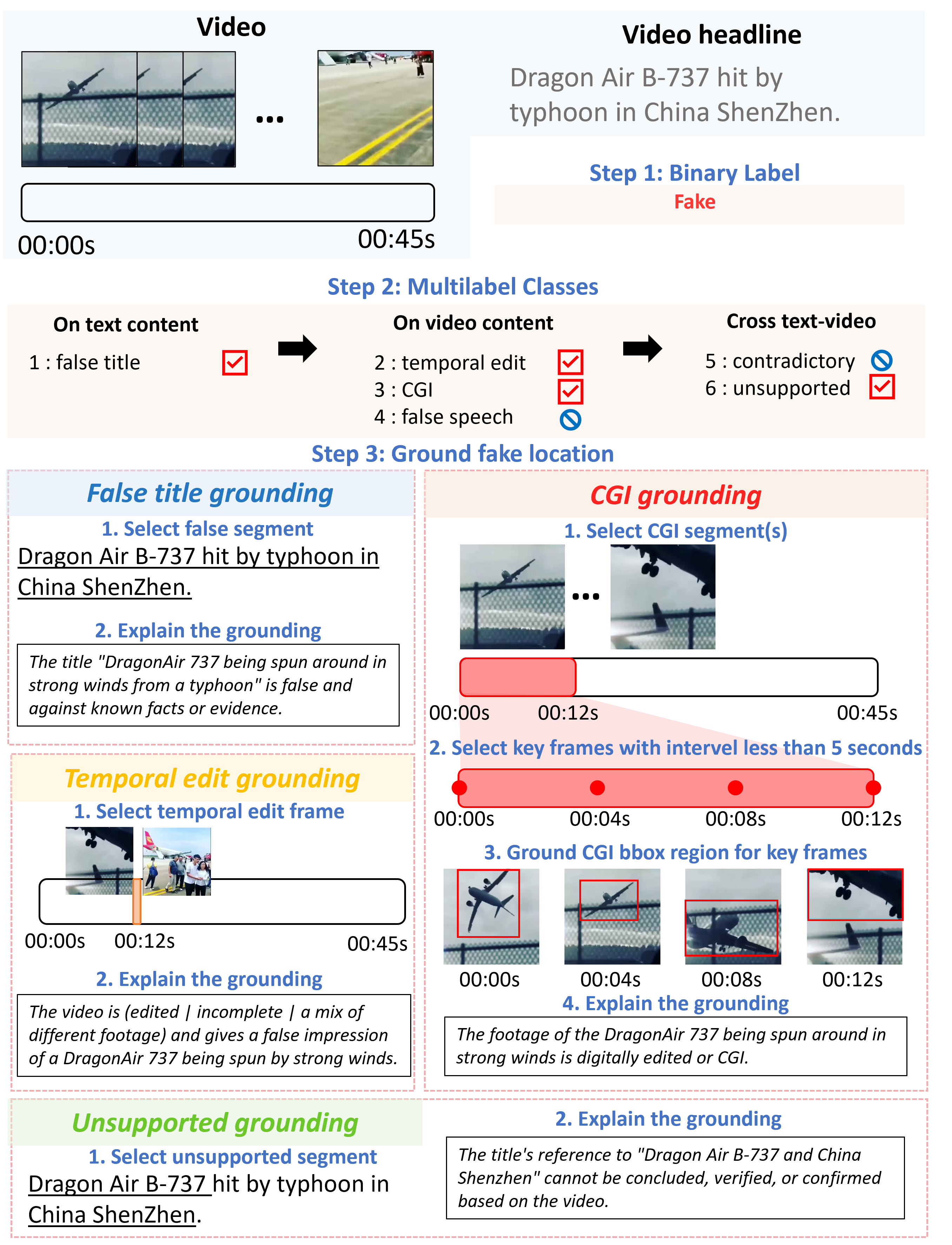
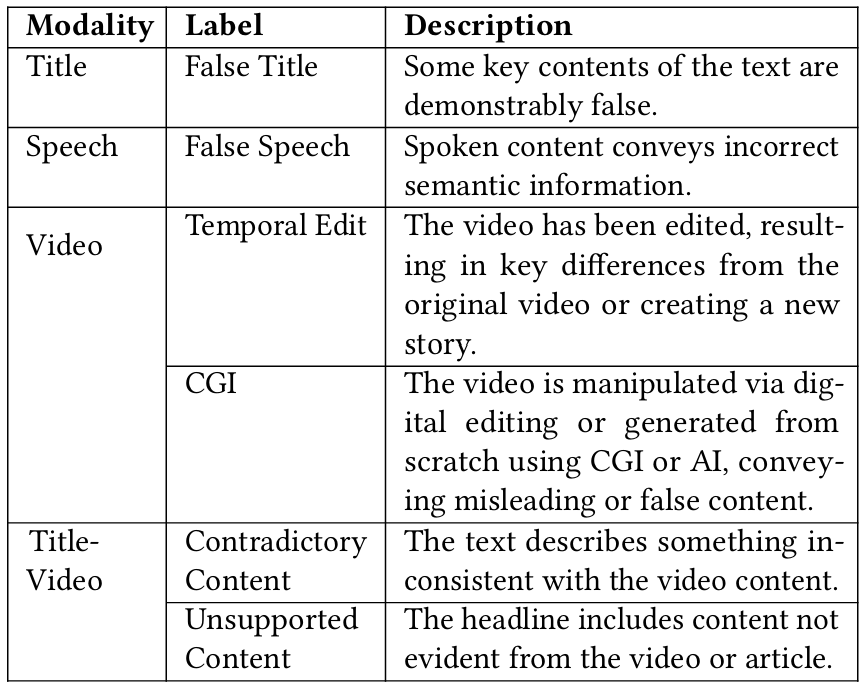
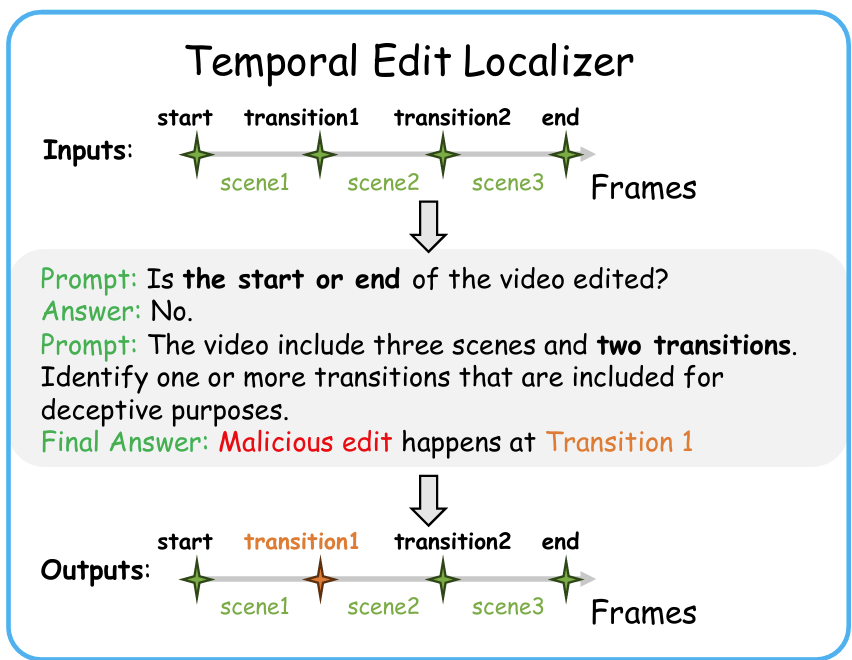
Overview. Our multi-modal benchmark contains 2,000+ fact-checked videos with fake
type and grounding annotations. Fake types include: (1) False
Title/False Speech - video title or spoken content
containing
demonstrably false claims; (2) Temporal Edit - videos altered
to distort
event chronologies or fabricate deceptive narratives; (3) CGI -
digitally manipulated or generated synthetic media; (4) Contradictory
Content - text-video semantic mismatches; and (5) Unsupported Content
- headlines lacking evidentiary support in video content. The dataset offers a unified benchmark for
fake content classification and localization.